



Modelo Open Source de Detecção de Assinaturas Manuscritas

Por Samuel Lima Braz, engenheiro de IA na Tech4Humans.

Este artigo apresenta o desenvolvimento, treinamento e implantação de um modelo open source para a detecção de assinaturas manuscritas em documentos, com o objetivo de automatizar o processamento documental.
Para tanto, foi realizada uma análise comparativa de diversas arquiteturas de detecção de objetos, a criação e pré-processamento de um dataset composto por duas bases públicas, a otimização de hiperparâmetros utilizando o Optuna e a avaliação extensiva do modelo final.
Por fim, discute-se a implantação do modelo por meio do Triton Inference Server e sua disponibilização no Hugging Face Hub. Os resultados demonstram um bom equilíbrio entre precisão, recall e tempo de inferência, evidenciando a viabilidade da solução proposta.
1. Introdução
A automação no processamento de documentos tem ganhado destaque em diversas aplicações industriais e acadêmicas. Neste contexto, a detecção de assinaturas manuscritas apresenta certos desafios, incluindo orientação, iluminação, ruído, layout do documento, letras cursivas no conteúdo do documento, assinaturas em posições variadas, entre outros. Este trabalho descreve o desenvolvimento completo de um modelo para essa tarefa, destacando a seleção e comparação de arquiteturas, a criação e manipulação de datasets, o treinamento com ajuste de hiperparâmetros e a implantação do modelo em ambiente de produção.
2. Metodologia
2.1 Arquiteturas de Detecção de Objetos
A detecção de objetos em visão computacional melhorou significativamente, equilibrando velocidade e precisão para casos de uso como direção autônoma e aplicações de vigilância. O campo evoluiu rapidamente, e as arquiteturas geralmente se enquadram em certos paradigmas:
Detectores de Duas Etapas Baseados em CNN: Modelos da família R-CNN primeiro identificam regiões potenciais de objetos antes de classificá-los.
Detectores de Uma Etapa Baseados em CNN: Modelos da família YOLO e SSD que preveem caixas delimitadoras e classes em uma única passagem.
Detectores Baseados em Transformadores: Modelos baseados em DETR que aplicam mecanismos de atenção para detecção de ponta a ponta.
Arquiteturas Híbridas: Sistemas que combinam a eficiência das CNNs com o entendimento contextual dos Transformadores.
Detectores de Zero-shot: Capazes de reconhecer classes de objetos desconhecidas sem treinamento específico.
Tabela 2: Principais Arquiteturas de Redes Neurais para Detecção de Objetos
Confira esta tabela de classificação para as últimas atualizações sobre modelos de detecção de objetos: Tabela de Classificação de Detecção de Objetos.
Contexto e Evolução
A detecção de objetos tem evoluído significativamente ao longo dos anos, passando de modelos convencionais baseados em redes neurais convolucionais (CNN), como o Faster R-CNN e o SSD, para abordagens mais modernas fundamentadas em transformadores, como o DETR, lançado em 2020 pela equipe do Facebook AI. Essa transição busca aprimorar a precisão por meio do uso de modelos de transformadores, que possuem uma capacidade superior para capturar o contexto global das imagens. Modelos mais recentes, como o RT-DETR e o YOLOv11, continuam a aperfeiçoar esse equilíbrio, com foco no desempenho em tempo real e na acurácia.
Série YOLO
O You Only Look Once (YOLO) foi apresentado em 2016 por Joseph Redmon, Santosh Divvala, Ross Girshick e Ali Farhadi, marcando uma revolução na área de detecção de objetos ao propor um detector de etapa única. Diferentemente das abordagens de duas etapas, que inicialmente geram propostas de regiões e depois as classificam, o YOLO realiza a predição de caixas delimitadoras e classes de objetos em uma única passagem pela rede neural. Esse design confere ao YOLO uma velocidade excepcional, tornando-o ideal para dispositivos de borda e aplicações de computação em tempo real, como vigilância de segurança, monitoramento de tráfego e inspeção industrial.

Ano após ano, a família YOLO tem sido aprimotada repetidamente. Cada versão trouxe novos métodos e avanços para compensar as fraquezas das anteriores:
YOLOv1: Pioneira na eliminação de propostas de região ao escanear a imagem inteira em uma única passagem (forward pass), capturando contexto global e local simultaneamente.
YOLOv2 e YOLOv3: Trouxeram avanços significativos, como Redes de Pirâmide de Características (FPN), treinamento multiescala e uso de caixas-âncora (anchor boxes), aprimorando a detecção de objetos de diferentes tamanhos.
YOLOv4: Marcou uma grande atualização arquitetural ao adotar a backbone CSPDarknet53-PANet-SPP e integrar técnicas inovadoras, como bag of specials, bag of freebies, algoritmos genéticos e módulos de atenção, elevando precisão e velocidade.
YOLOv5: Embora arquiteturalmente semelhante à YOLOv4, sua implementação em PyTorch e o processo de treinamento simplificado no framework Ultralytics impulsionaram sua adoção em larga escala.
YOLO-R, YOLO-X, YOLOv6 e YOLOv7: Exploraram aprendizagem multitarefa (YOLO-R), detecção sem âncoras (anchor-free), cabeças decoupled, reparametrização, destilação de conhecimento e quantização, permitindo melhor escalabilidade e otimização.
YOLOv8 e YOLO-NAS: A YOLOv8 aprimora a YOLOv5 com mudanças como a substituição da CSPLayer pelo módulo C2f e funções de perda otimizadas para detecção de objetos pequenos. Já a YOLO-NAS destaca-se por ser gerada via busca neural de arquitetura (NAS), usando blocos quantization-aware para equilibrar velocidade e precisão.
Um desafio da arquitetura YOLO é a proliferação de versões, já que o nome pode ser usado livremente, e nem todas as versões recentes trazem melhorias significativas. Na prática, quando um novo modelo é lançado com o nome YOLO, ele frequentemente exibe métricas superiores, mas as diferenças tendem a ser mínimas.

Além disso, um modelo com métricas superiores em conjuntos de avaliação genéricos (como COCO) não garante melhor desempenho em casos de uso específicos. Variáveis como tamanho do modelo, tempo de inferência e treinamento, compatibilidade com bibliotecas/hardware, e características dos dados também influenciam.

A família YOLO destaca-se pelo design unificado e otimizado, permitindo implantação em dispositivos de recursos limitados e aplicações em tempo real. Contudo, sua diversidade de versões cria desafios na escolha do modelo ideal para cada cenário.
DETR
O DEtection TRansformer (DETR) introduz uma abordagem inovadora ao combinar redes neurais convolucionais com arquitetura transformer, eliminando etapas tradicionais e complexas de pós-processamento, como a Supressão Não Máxima (NMS).
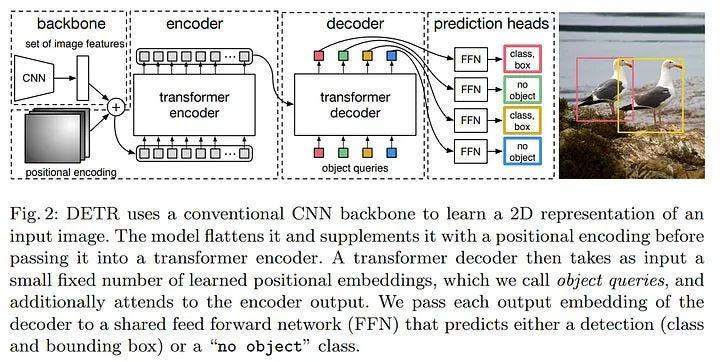
A arquitetura DETR pode ser dividida em quatro componentes principais:
Backbone (ex.: ResNet):
Função: Extrair um feature map (mapa de características) rico em informações semânticas e espaciais da imagem de entrada.
Saída: Um conjunto de vetores bidimensionais (feature map) que serve como entrada para o módulo transformer.
2. Codificador-Decodificador Transformer:
Codificador:
- Função: Processar o feature map da backbone por meio de camadas de autoatenção multihead e feed-forward, capturando relações contextuais e globais entre diferentes regiões da imagem.Decodificador:
- Função: Utilizar um conjunto fixo de object queries (vetores de consulta que representam candidatos a objetos) para refinar iterativamente as previsões de bounding boxes e classes.
- Saída: Um conjunto final de previsões, onde cada query corresponde a uma caixa delimitadora e sua respectiva classe.
3. Rede Neural Feed-Forward (FFN):
Função: Para cada query processada pelo decodificador, a FFN gera as previsões finais, incluindo coordenadas normalizadas da caixa (x, y, largura e altura) e scores de classificação (com uma classe especial para “nenhum objeto”).
4. Raciocínio Conjunto (Joint Reasoning):
Característica: O DETR processa todos os objetos simultaneamente, explorando relações pairwise (entre pares) para resolver ambiguidades como sobreposição de objetos, dispensando técnicas de pós-processamento como a NMS.
O DETR original enfrentou desafios como convergência lenta e desempenho subótimo na detecção de objetos pequenos. Para superar essas limitações, surgiram variantes aprimoradas:
Deformable DETR:
- Deformable Attention: Foca a atenção em pontos de amostragem fixos próximos a cada referência, melhorando eficiência e permitindo detectar detalhes finos em imagens de alta resolução.
- Módulo Multiescala: Incorpora feature maps de diferentes camadas da backbone, ampliando a capacidade de detectar objetos de tamanhos variados.

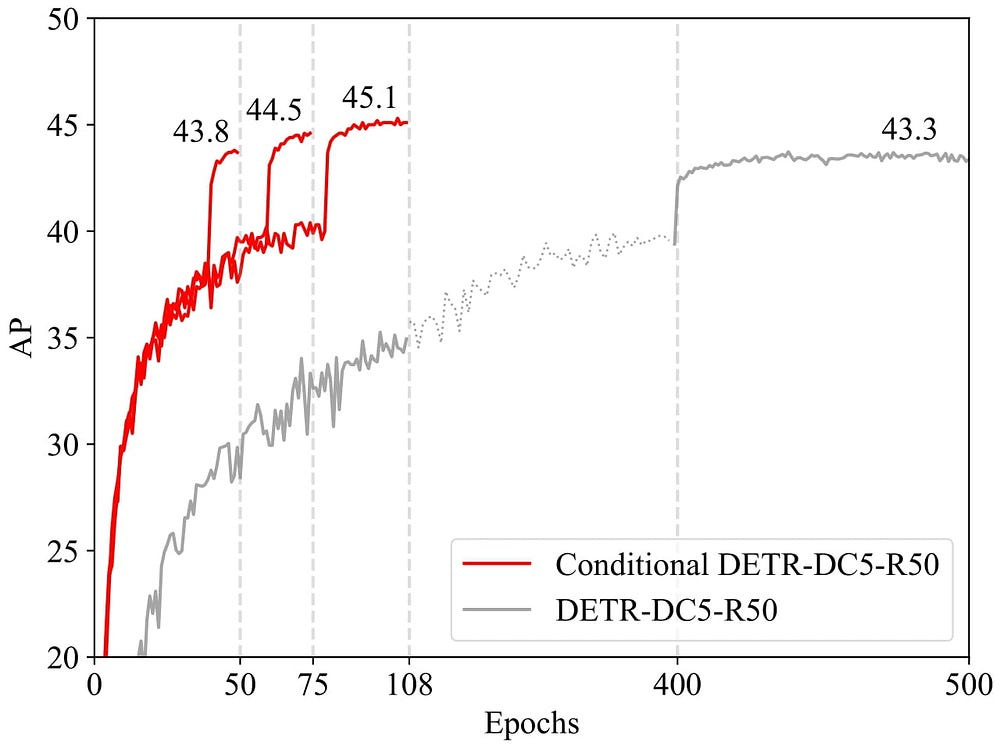
Conditional DETR:
- Melhoria na Convergência: Introduz cross-attention condicional no decodificador, tornando as object queries mais específicas à imagem de entrada e acelerando o treinamento (com convergência até 6.7× mais rápida).
Assim, o DETR e suas variantes representam uma mudança de paradigma na detecção de objetos, aproveitando o poder dos transformers para capturar relações globais e contextuais de forma end-to-end, simplificando o pipeline ao eliminar etapas manuais de pós-processamento.
RT-DETR
O RT-DETR (Real-Time DEtection TRansformer) é um modelo baseado em transformer projetado para detecção de objetos em tempo real, estendendo a arquitetura DETR com otimizações de velocidade e eficiência.

Codificador Híbrido:
O RT-DETR utiliza um codificador híbrido que combina interação intraescala e fusão interescala. Esse design permite processar eficientemente características em diferentes escalas, capturando detalhes locais e relações globais.
Essa abordagem é particularmente vantajosa para detectar objetos de tamanhos variados em cenas complexas, um desafio para modelos transformer anteriores.
2. Eliminação da NMS:
Assim como o DETR, o RT-DETR dispensa a Supressão Não Máxima (NMS) ao prever todos os objetos simultaneamente. Essa abordagem end-to-end simplifica o pipeline de detecção e reduz o custo computacional de pós-processamento.
3. Otimização para Tempo Real:
O RT-DETR alcança latência média (10–200 ms), sendo adequado para aplicações em tempo real, como direção autônoma e monitoramento por vídeo, mantendo precisão competitiva.
O RT-DETR aproxima-se tanto de modelos baseados em CNN de alta velocidade (como YOLO) quanto de modelos transformer focados em precisão.
YOLOS
O YOLOS (You Only Look at One Sequence) introduz uma abordagem inovadora para detecção de objetos baseada em transformers, inspirada no Vision Transformer (ViT). Diferente de modelos tradicionais baseados em CNN, o YOLOS reconceitualiza a detecção ao tratar imagens como sequências de patches (segmentos), aproveitando a capacidade de processamento sequencial dos transformers.

Backbone Vision Transformer (ViT):
O YOLOS utiliza uma backbone ViT, que divide a imagem em patches de tamanho fixo (ex.: 16×16 pixels). Cada patch é tratado como um token, permitindo que o transformer processe a imagem como uma sequência e capture dependências de longo alcance.
2. Processamento Baseado em Patches:
Ao converter a imagem em uma sequência de patches, o YOLOS processa eficientemente entradas de alta resolução e detecta objetos em diferentes escalas, adaptando-se a diversas tarefas de detecção.
3. Object Queries:
Assim como o DETR, o YOLOS emprega object queries (vetores de consulta) para prever bounding boxes e classes diretamente. Isso elimina a necessidade de anchor boxes ou NMS, alinhando-se à filosofia end-to-end da detecção com transformers.
4. Variantes de Eficiência:
O YOLOS oferece variantes como yolos-tiny, -small e -base, permitindo equilibrar custo computacional e desempenho conforme a aplicação.

Eu acho essa figura muito interessante. Ela ilustra como os tokens [DET] se especializam em focar objetos de tamanhos específicos e regiões distintas da imagem. Esse comportamento adaptativo destaca a eficácia do modelo em tarefas de detecção, permitindo alocar dinamicamente recursos conforme características espaciais e de escala dos objetos.
2.2. Dataset e Pré-processamento
O dataset foi constituído pela combinação de dois conjuntos públicos:
Tobacco800: Subconjunto da Coleção de Teste de Processamento de Imagens de Documentos Complexos (CDIP), com imagens digitalizadas da indústria do tabaco. O groundtruth inclui anotações de assinaturas e logotipos.
signatures-xc8up: Parte do Roboflow 100, contendo 368 imagens anotadas para detecção de assinaturas manuscritas.
Roboflow
A plataforma Roboflow foi utilizada para a manipulação, pré-processamento e rotulagem das imagens. Entre os recursos empregados, destacam-se:
Divisão do Dataset:
- Treinamento: 1.980 imagens (70%)
- Validação: 420 imagens (15%)
- Teste: 419 imagens (15%)Pré-processamento:
- Auto-orientação e redimensionamento para 640×640 pixels.Aumentações:
- Rotação (90° e variações entre ±10°)
- Cisalhamento (±4° horizontal e ±3° vertical)
- Ajustes de brilho e exposição
- Aplicação de desfoque e ruído
Essas técnicas contribuem para a robustez do modelo em cenários variados.
Disponibilidade do Dataset:

2.3. Processo de Treinamento e Seleção de Modelos
Foram avaliados diversos modelos a partir de experimentos realizados com 35 épocas de treinamento e configurações homogêneas de batch size e learning rate, conforme capacidade computacional disponível. A tabela a seguir sintetiza os resultados obtidos para métricas como tempo de inferência (CPU), mAP@50, mAP@50–95 e tempo total de treinamento:

Destaques:
Melhor mAP@50:
conditional-detr-resnet-50(93.65%)Melhor mAP@50–95:
yolov8m(66.55%)Menor Tempo de Inferência:
yolov10n(73.86 ms)
Os experimentos completos estão disponíveis no Weights & Biases.
Como resultado, observamos um comportamento diferente dos benchmarks generalistas, nos quais as versões maiores dos modelos tendem a apresentar melhorias incrementais nos resultados. Nesta experimentação, modelos menores, como o YOLOv8n e o YOLOv11s, obtiveram resultados satisfatórios e comparáveis às suas versões maiores.
Além disso, as arquiteturas puramente convolucionais demonstraram ser mais rápidas do que as baseadas em Transformers, tanto na inferência quanto no treinamento, mantendo uma precisão semelhante.
2.4. Otimização de Hiperparâmetros
Devido ao bom desempenho inicial e à facilidade de exportação, o modelo YOLOv8s foi selecionado para ajuste fino dos hiperparâmetros utilizando o Optuna. Foram realizadas 20 tentativas, com a métrica F1 do conjunto de teste definida como função objetivo. A configuração dos parâmetros incluiu:
dropout = trial.suggest_float("dropout", 0.0, 0.5, step=0.1)
lr0 = trial.suggest_float("lr0", 1e-5, 1e-1, log=True)
box = trial.suggest_float("box", 3.0, 7.0, step=1.0)
cls = trial.suggest_float("cls", 0.5, 1.5, step=0.2)
opt = trial.suggest_categorical("optimizer", ["AdamW", "RMSProp"])Os resultados podem ser visualizados aqui: Hypertuning Experiment.
A figura a seguir ilustra a correlação entre os parâmetros e os resultados obtidos:

Após o ajuste, o melhor trial evidenciou as seguintes melhorias (comparando o modelo base com o melhor trial):

3. Avaliação e Resultados
A avaliação final do modelo foi realizada utilizando formatos ONNX (para inferência em CPU) e TensorRT (para GPU — T4). As principais métricas obtidas foram:
Precisão (Precision): 94.74%
Revocação (Recall): 89.72%
mAP@50: 94.50%
mAP@50–95: 67.35%
Quanto aos tempos de inferência:
ONNX Runtime (CPU): 171.56 ms
TensorRT (GPU — T4): 7.657 ms
A Figura 13 apresenta a comparação gráfica entre as métricas avaliadas:

O Modelo Base — Fase 1 (☆) representa o modelo obtido no treinamento feito na etapa de seleção.
4. Implantação e Publicação
Nesta seção, descrevemos o processo de implantação do modelo de detecção de assinaturas manuscritas utilizando o Triton Inference Server e a publicação do modelo e do conjunto de dados no Hugging Face Hub. O objetivo foi criar uma solução eficiente, econômica e segura para disponibilizar o modelo em um ambiente de produção, ao mesmo tempo em que tornamos o trabalho acessível à comunidade por meio de repositórios públicos, seguindo princípios de ciência aberta.
4.1. Servidor de Inferência
O Triton Inference Server foi escolhido como a plataforma de implantação devido à sua flexibilidade, eficiência e suporte a múltiplos frameworks de machine learning, como PyTorch, TensorFlow, ONNX e TensorRT. Ele permite realizar inferências tanto em CPU quanto em GPU, além de oferecer ferramentas nativas para análise de desempenho e otimização, tornando-o ideal para a implantação de modelos em escala.
O repositório com as configurações do servidor e códigos utilitários está disponível em: https://github.com/tech4ai/t4ai-signature-detect-server
Configuração do Servidor
Para implementar o Triton, optamos por uma abordagem otimizada utilizando um container Docker customizado. Em vez de utilizar a imagem padrão, que inclui todos os backends e resulta em um tamanho de 17.4 GB, adicionamos apenas os backends necessários para este projeto: Python, ONNX e OpenVINO. Essa otimização reduziu o tamanho da imagem para 12.54 GB melhorando a eficiência do processo de implantação. Para cenários que demandem inferência em GPU, seria necessário incluir o backend TensorRT e utilizar o modelo no formato .engine, mas, neste caso, priorizamos a execução em CPU para reduzir custos e simplificar a infraestrutura.
O servidor foi configurado com o seguinte comando de inicialização, adaptado para garantir controle explícito dos modelos e segurança:
tritonserver \
--model-repository=${TRITON_MODEL_REPOSITORY} \
--model-control-mode=explicit \
--load-model=* \
--log-verbose=1 \
--allow-metrics=false \
--allow-grpc=true \
--grpc-restricted-protocol=model-repository,model-config,shared-memory,statistics,trace:admin-key=${TRITON_ADMIN_KEY} \
--http-restricted-api=model-repository,model-config,shared-memory,statistics,trace:admin-key=${TRITON_ADMIN_KEY}O modo explicit permite carregar e descarregar modelos dinamicamente via protocolos HTTP/GRPC, oferecendo flexibilidade para atualizações futuras sem reiniciar o servidor.
Restrição de Acesso
O Triton é configurado para para limitar o acesso a endpoints administrativos sensíveis, como model-repository, model-config, shared-memory, statistics e trace.
Esses endpoints só podem ser acessados por requisições que incluam o cabeçalho admin-key com o valor correto. Essa restrição protege operações administrativas, enquanto as requisições de inferência permanecem abertas a todos os usuários.
Ensemble Model
Desenvolvemos um Ensemble Model no Triton para integrar o modelo YOLOv8 (no formato ONNX) com scripts de pré e pós-processamento, criando um pipeline de inferência completo executado diretamente no servidor. Essa abordagem reduz a latência ao eliminar a necessidade de múltiplas chamadas de rede e simplifica a integração do lado do cliente. O fluxo do Ensemble Model inclui:
Pré-processamento (backend Python):
- Decodificação da imagem de BGR para RGB.
- Redimensionamento para 640x640 pixels.
- Normalização dos valores dos pixels (divisão por 255.0).
- Transposição para o formato [C, H, W].Inferência (modelo ONNX):
- O modelo YOLOv8 realiza a detecção das assinaturas.Pós-processamento (backend Python):
- Transposição dos outputs do modelo.
- Filtragem de caixas delimitadoras com pontuação acima do limiar de confiança (confidence threshold).
- Aplicação de Non-Maximum Suppression (NMS) com um limiar de IoU para eliminar detecções redundantes.
- Formatação dos resultados no formato [x, y, w, h, score].

Os scripts de pré e pós-processamento são tratados como “modelos” pelo Triton e executados no backend Python, permitindo flexibilidade para ajustes ou substituições sem alterar o núcleo do modelo. O Ensemble Model encapsula todo o pipeline em um único ponto de entrada, otimizando o desempenho e a usabilidade.
Pipeline de Inferência
No repositório do projeto, desenvolvemos múltiplos scripts de inferência para interagir com o Triton, utilizando diferentes métodos:
Triton Client: Inferência via SDK do Triton.
Vertex AI: Integração com um endpoint da Google Cloud Vertex AI.
HTTP: Requisições diretas ao servidor Triton via protocolo HTTP.
Esses scripts foram criados para testar o servidor e facilitar integrações futuras. Além disso, o pipeline inclui ferramentas adicionais:
Interface Gráfica (GUI): Desenvolvida com Gradio, permite testes interativos do modelo, com visualização dos resultados em tempo real. Exemplo de uso:
python signature-detection/gui/inference_gui.py --triton-url {triton_url}Interface de Linha de Comando (CLI): Permite realizar inferências em conjuntos de dados, calcular métricas de tempo e gerar relatórios. Exemplo de uso:
py python signature-detection/inference/inference_pipeline.py O pipeline foi projetado para ser modular e extensível, suportando experimentações e implantações em diferentes ambientes, desde soluções locais até baseadas em nuvem.
4.2. Hugging Face Hub
O modelo de detecção de assinaturas foi publicado no Hugging Face Hub para torná-lo acessível à comunidade e cumprir os requisitos de licenciamento do Ultralytics YOLO. O repositório do modelo inclui:
Model Card:
Um documento detalhado que descreve o processo de treinamento, métricas de desempenho (como precisão e recall) e diretrizes de uso.
Arquivos do modelo disponíveis nos formatos PyTorch, ONNX e TensorRT, permitindo flexibilidade na escolha do backend de inferência.
Space de Demonstração:
Uma interface interativa desenvolvida com Gradio, onde usuários podem testar o modelo enviando imagens e visualizando as detecções em tempo real.
Conjunto de Dados:
O conjunto de dados utilizado para treinamento e validação também foi hospedado no Hugging Face, aleḿ do Roboflow, acompanhado de documentação completa e arquivos em formatos acessivéis.
5. Conclusão
Este trabalho demonstrou a viabilidade de desenvolver um modelo eficiente para detecção de assinaturas manuscritas em documentos, combinando técnicas modernas de visão computacional com ferramentas robustas de implantação. A análise comparativa de arquiteturas revelou que modelos baseados em YOLO, em especial o YOLOv8s, oferecem um equilíbrio ideal entre velocidade e precisão para o cenário estudado, alcançando 94,74% de precisão e 89,72% de recall após otimização com Optuna. A integração do Triton Inference Server permitiu a criação de um pipeline de inferência escalável, enquanto a publicação no Hugging Face Hub garantiu transparência e acessibilidade, alinhando-se aos princípios de ciência aberta.
A solução proposta tem aplicações imediatas em setores como jurídico, financeiro e administrativo, onde a automação da verificação de documentos reduz custos operacionais e minimiza erros humanos. A capacidade de inferência em CPU (171,56 ms) e GPU (7,65 ms) torna o modelo versátil para implantações em diferentes infraestruturas, desde servidores em nuvem até dispositivos de borda.
Como limitações, destaca-se a dependência da qualidade das anotações do dataset e a necessidade de validação em documentos com layouts complexos ou assinaturas parcialmente ocultas. Futuros trabalhos podem explorar:
A expansão do dataset com imagens de maior diversidade cultural e tipográfica.
A adaptação do modelo para detecção de outros elementos documentais (carimbos, selos).
Por fim, a disponibilização aberta do código, modelo e dataset no Hugging Face Hub e GitHub incentiva a colaboração da comunidade, acelerando a evolução de soluções similares. Este projeto não apenas valida a eficácia das abordagens testadas, mas também estabelece um blueprint para a implantação prática de modelos de detecção em produção, reforçando o potencial da IA para transformar workflows tradicionais.
Muito bom!