



Guardrails para LLMs: Estudo sobre o Uso e Ferramentas Disponíveis

Conceitos e Fundamentos
O que são Guardrails?
Guardrails são estruturas projetadas para prevenir e mitigar resultados indesejados. Este termo é amplamente utilizado em diversas áreas para se referir a mecanismos de proteção, como diretrizes, políticas e procedimentos que asseguram que processos, comportamentos ou sistemas permaneçam em um caminho seguro e intencionado.
No contexto da inteligência artificial, os guardrails são usados para garantir que os Modelos de Linguagem de Grande Escala (LLMs) operem dentro de limites éticos, legais e técnicos. Essas proteções são essenciais para evitar danos, como injeção de prompts, decisões tendenciosas e disseminação de desinformação, além de controlar vieses e alucinações do modelo. Basicamente, os guardrails atuam como uma camada entre o LLM e o usuário, verificando e controlando o conteúdo e a forma das respostas do LLM às perguntas do usuário.

Por que utilizar Guardrails?
A Engenharia de Prompt é uma prática eficaz para controlar a saída dos modelos de linguagem, e técnicas como Recuperação Assistida por Geração (RAG) podem reduzir alucinações, melhorando a precisão e a relevância das respostas. No entanto, essas técnicas, por si só, não são suficientes para resolver completamente esses problemas. Guardrails são necessários para garantir a confiabilidade das interações. Além disso, é crucial monitorar não apenas o comportamento do modelo, mas também verificar se os prompts enviados pelos usuários são livres de viés e não induzem a respostas tendenciosas.
Tipos de Guardrails:
Ethical and policy guardrails: Esses guardrails são essenciais para identificar e mitigar vieses nos modelos de linguagem, usando técnicas de detecção de vieses algorítmicos e filtros que evitam saídas ofensivas ou discriminatórias. Eles garantem que os modelos de IA operem de forma justa e inclusiva, respeitando a diversidade dos usuários. Sem essas proteções, há o risco de perpetuar preconceitos existentes, gerando consequências sociais graves.
Technical guardrails: Protegem os modelos contra injeção de prompt e alucinações, assegurando a integridade e precisão das respostas. Injeção de prompt refere-se ao uso de inputs maliciosos que podem manipular a saída do modelo de maneira prejudicial, enquanto alucinações são respostas incorretas ou irrelevantes geradas pelo modelo. Eles implementam verificações para prevenir inputs maliciosos e respostas incorretas ou irrelevantes, sendo cruciais para manter a confiabilidade e segurança dos modelos de linguagem.
Security guardrails: Esses guardrails garantem que os modelos de IA estejam em conformidade com regulamentações legais e políticas de proteção de dados pessoais e direitos do indivíduo. Isso inclui garantir que as interações do modelo estejam de acordo com leis como a GDPR na União Europeia e a LGPD no Brasil. Esses guardrails também protegem contra a divulgação não autorizada de informações sensíveis.
Vantagens:
Segurança: Os guardrails asseguram a proteção contra conteúdo inapropriado e garantem conformidade com leis e regulamentos específicos. Isso é crucial para manter um ambiente seguro e legalmente responsável.
Qualidade do Conteúdo: As respostas geradas pelo modelo tornam-se mais confiáveis e precisas. Isso aumenta a utilidade das interações e melhora a experiência do usuário.
Formato de Conteúdo: Garantia que as mensagens estejam no formato e estrutura desejada.
Depuração Facilitada: Facilita a identificação de pontos críticos onde saídas inesperadas ocorrem e permite entender melhor o porquê desses eventos.
Desvantagens/Limitações:
Habilidades: Guardrails não podem adicionar novas habilidades ao modelo; eles atuam apenas dentro das capacidades existentes. Se o modelo não tem habilidades como desenvolvimento de código, os guardrails não podem suprir essa falta.
Complexidade: Implementar guardrails pode ser complexo, especialmente com regras extensas e complicadas, exigindo esforço significativo em desenvolvimento e manutenção.
Restrições da Flexibilidade do Modelo: Guardrails podem limitar a flexibilidade do modelo, restringindo a gama de respostas possíveis. Isso pode ser uma desvantagem em contextos que requerem criatividade ou respostas variadas.
Exigência de Recursos e Tempo:A configuração e manutenção de guardrails demandam recursos extras, tanto em processamento quanto em tempo de desenvolvimento, podendo afetar a eficiência e o tempo de resposta do sistema.
Técnicas de Validação
Formato de Mensagem:
Validação do Tipo de Dados: Assegura que a entrada ou saída esteja no formato correto.
Estrutura e Formato: Garante que a estrutura da mensagem segue os padrões estabelecidos.
Filtro de Conteúdo:
Detecção de Conteúdo Impróprio: Filtra mensagens para identificar e bloquear conteúdo inadequado.
Correspondência de Palavras-Chave: Utiliza palavras-chave e padrões para reconhecer material potencialmente ofensivo.
Detecção de Prompt Injection: Implementa técnicas para identificar e mitigar tentativas de manipulação através de prompts maliciosos.
Coerência e Semântica:
Contextualidade: Verifica se o conteúdo faz sentido dentro do contexto fornecido.
Consistência Lógica: Implementa regras para assegurar a precisão e coerência da resposta gerada.
Validação de Conformidade:
Padrões Legais e Modelos de Conformidade: Assegura que a mensagem esteja em conformidade com leis e regulamentos, como privacidade de dados.
Verificação de Fatos:
Precisão dos Fatos: Valida a confiabilidade e precisão das informações fornecidas.
Base de Dados: Confere se os fatos apresentados são verídicos, comparando com bases de dados conhecidas.
Modelos de Verificação: Utiliza modelos externos para garantir que as informações não são fabricadas pelo modelo.
Ferramentas de Guardrails

Nvidia NeMo
1. Definição:
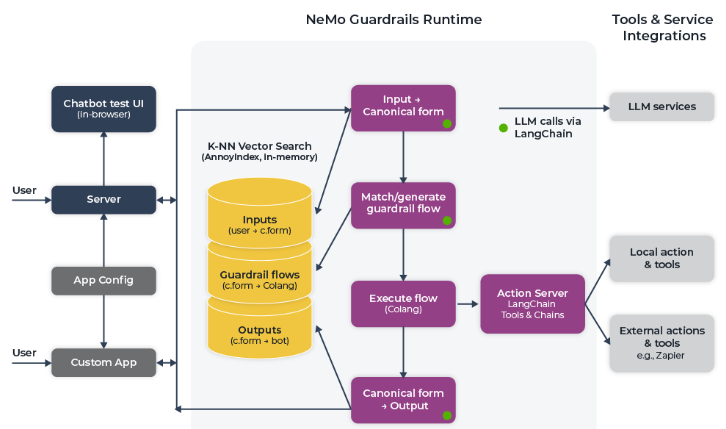
Nvidia NeMo funciona como uma camada intermediária de segurança para Modelos de Linguagem de Grande Escala (LLMs). Ele utiliza a linguagem Colang, projetada especificamente para estabelecer restrições e fluxos de trabalho que guiem o funcionamento do LLM de maneira segura e controlada. A base de seu funcionamento é um método baseado em K-Nearest Neighbours (KNN), que compara os inputs com formas canônicas armazenadas em um banco de vetores.
NeMo também inclui um conjunto de moderações pré implementadas dedicadas, por exemplo, à verificação de fatos, prevenção de alucinações em respostas e moderação de conteúdo.
2. K-nearest neighbors (KNN):
O K-Nearest Neighbours (KNN) é um método de aprendizado de máquina baseado em instâncias utilizado para classificação e regressão. No contexto do Nvidia NeMo, KNN é usado para comparar inputs de texto com formas canônicas armazenadas em um banco de vetores, visando encontrar as entradas mais semelhantes em termos de significado e contexto.
Os principais elementos de um script Colang são: user canonical form, bot canonical form e fluxos de diálogo. Todos esses três tipos de definições também são indexados em um vector database para permitir uma pesquisa eficiente de vizinhos mais próximos (KNN) quando selecionam os poucos exemplos para o prompt. Quando uma mensagem é recebida do usuário ou do bot, ela é codificada no mesmo espaço vetorial das formas canônicas. A similaridade semântica é calculada para identificar os enunciados mais relevantes e suas respectivas formas canônicas. A escolha de qual forma canônica usar como base para a resposta é feita com base na similaridade semântica.
3. Colang:
O NeMo Guardrails utiliza a linguagem de modelagem Colang, uma mini linguagem desenvolvida para facilitar a criação de fluxos de diálogos e implementar proteções de segurança em sistemas conversacionais. Colang é projetada para ser simples e flexível, com poucas construções, o que facilita o desenvolvimento de fluxos de diálogos.
3.1. Funcionamento da Colang
Flow: Usando Colang, é possível definir fluxos de diálogos através de Canonical Form e Utterances. As formas canônicas são armazenadas em um espaço vetorial e os enunciados são mapeados para essas formas canônicas.
Variáveis e Fluxo: permite a definição de variáveis usando o caractere.
Actions e Agents: Inclui actions, que são funções executáveis. Para usar ações, permitindo que o modelo utilize ferramentas externas de maneira eficiente. Em caso de guardrails assíncronos, funções assíncronas devem ser usadas para evitar erros de execução.
4. Limitações/Desvantagens
Soluções autônomas: NeMo Guardrails não é recomendado como uma solução autônoma. É importante integrar "embedded rails" nos modelos para auxiliar na segurança. Para agentes de diálogo controláveis e orientados a tarefas, pode ser difícil desenvolver modelos personalizados para todas as ferramentas possíveis e trilhos específicos (topical rails). Portanto, em tais contextos, o NeMo Guardrails continua sendo uma solução viável.
Custos Extras e Latência: O NeMo utiliza abordagem de solicitação de Cadeia de Pensamento (CoT) em três etapas usada no runtime dos guardrails causa custos adicionais e latência, já que é um processo sequencial. O uso de prompts mais complexos pode aumentar a latência, embora seja possível optar por prompts mais simples para reduzir este impacto.
Lista Limitada de Modelos Suportados: Atualmente, apenas uma lista limitada de modelos é suportada pelo NeMo, o que pode restringir sua aplicabilidade em diferentes cenários.
5. Vantagens:
Flexibilidade e Rails Personalizados: É possível definir quais rails serão utilizados e quais os comportamentos do modelo, permitindo uma personalização do guardrail.
Integração de Diferentes Modelos e Ferramentas: Permite a integração eficiente de diferentes modelos de linguagem e ferramentas externas, ampliando a funcionalidade e versatilidade do sistema.
Controle do Fluxo do Diálogo: Têm-se controle detalhado sobre o fluxo do diálogo, facilitando a criação de interações mais dirigidas e seguras.
Guardrails AI
1. Definição
O Guardrails AI é um framework desenvolvido em Python com o objetivo de auxiliar na construção de aplicativos confiáveis e seguros. Guardrails é uma estrutura projetada para validar e estruturar dados provenientes de modelos de linguagem. Oferece uma gama de validações que variam de checagens simples, como correspondência de regex, até verificações complexas, como análise de concorrentes.
2. Guardrails Hub
Guardrails Hub é uma coleção de medidas pré-criadas que fornecem tipos específicos de validadores para facilitar a construção de aplicativos confiáveis. Além de oferecer validadores pré-definidos, o Hub permite que os desenvolvedores agrupem esses validadores tanto para entrada quanto para saída de dados, assegurando que todo o processo esteja sob medidas de segurança e consistência rigorosas.
3. Principais concepções:
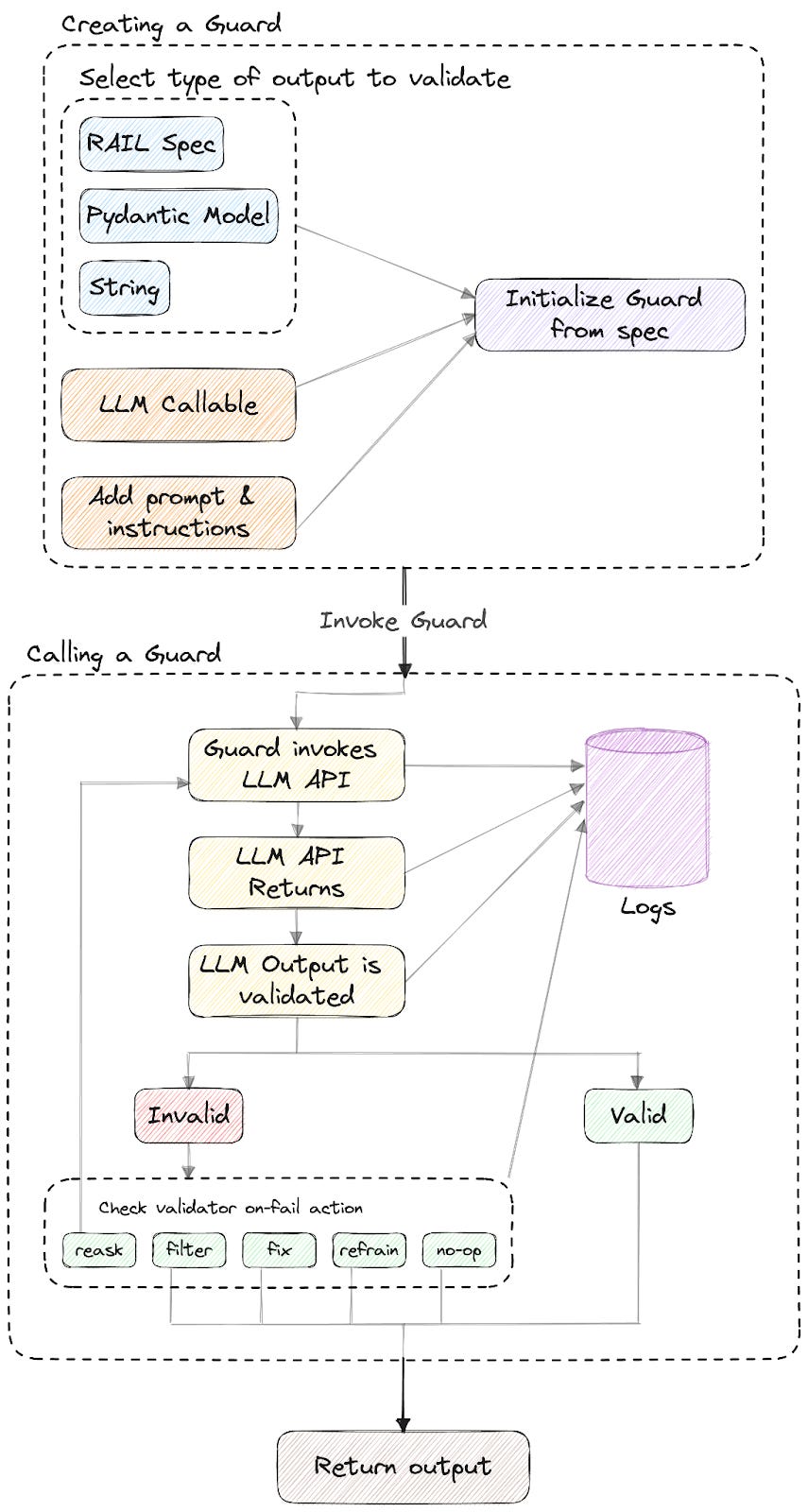
Guard: O objeto guard é a principal interface do Guardrails AI. Ele é responsável por executar o mecanismo de validação, agrupando as chamadas de LLMs, orquestrando a validação dos resultados e monitorando o histórico de chamadas. Para o seu uso primeiro processo é inicialize_guard, depois ele pode ser chamado usando um modelo LLM e uma mensagem, a chamada irá retornar um objeto GuardResponse, que possui a saída do LLM, a saída validada e se a validação foi bem sucedida ou não. O LLM também pode ser chamado separadamente, assim será realizado um pós processamento.
Validators: Especificam os critérios para medir se os resultados são válidos, bem como as ações necessárias para quando não são válidos. Também é possível criar validators personalizados e adicionar ao Guard. Os validators disponíveis podem ser encontrados no Guardrails Hub.
Logs e Histórico: Todas as chamadas do Guard são registradas internamente, sendo possível acessar o histórico dessas informações.
Remote Validation Inference: Há áreas que, quando não otimizadas, aumentam a latência. As duas principais são: o gerenciamento do Guard e modelos de ML. Para contornar o problema, a ferramenta oferece uma interface que permite separar a coordenação da execução das validações em ML.
4. Limitações/Desvantagens:
Mensurar Latência: O hub conta com diferentes técnicas de guardrails que podem ser escolhidas de acordo com a necessidade, isso dificulta saber qual a latência do uso.
5. Vantagens:
Open source
Integração: Possui integração com várias ferramentas, incluindo o Lite LLM
Suporte a LLMs: Suporta uma alta variedade de modelos, incluindo os open-source. Isso se deve também por ter integração com o Lite LLM.
Customizável: Sua variedade de validadores disponíveis no hub possibilita criar um Guard customizado para aplicação. Além disso, também é possível criar os próprios validadores.
Otimização: Ao permitir a execução de validação em endpoints remotos otimizados, pode-se melhorar a performance de modelos de ML que seriam lentos em hardware local menos poderoso.
Llama Guard
1. Descrição:
Llama Guard é uma solução desenvolvida pela Meta usando a arquitetura Llama2-7b com foco em aumentar a segurança de sistemas conversacionais. Trata-se de um modelo ajustado (fine-tuned) que recebe entradas e saídas de sistemas de linguagem (LLMs) e classifica essas informações em diversas categorias. Seu objetivo principal é atuar como guardrails de entrada-saída, ajudando a identificar e mitigar conteúdos inseguros.
2. Funcionamento:
O Llama Guard pode classificar tanto os prompts (entradas) quanto as respostas (saídas) de sistemas de linguagem (LLMs). Ele recebe esses conteúdos e procede a uma avaliação, gerando um texto que indica se são seguros ou inseguros. Quando um conteúdo é classificado como inseguro, o sistema especifica as subcategorias violadoras conforme uma política predefinida.
3. Taxonomia Específica:
O modelo foi ajustado para classificar conteúdo em 6 categorias principais: Violência, Conteúdo Sexua, Armas, Substâncias Controladas, Suicídio e Planejamento Criminoso.
4. Limitações
Confiabilidade: A classificação do conteúdo depende inteiramente da capacidade de compreensão do LLM, o que pode não ser sempre confiável.
Customização: Não tem abertura para customização e inserção de outras funcionalidades.
Latência: Pode ser ter uma latência maior que os demais já que usa um LLM para verificar o conteúdo.
5. Vantagens
Open Source
Fácil implementação

TruLens
1. Definição
O TruLens foi desenvolvido pela TruEra e se trata de um kit de ferramentas open-source para desenvolver, avaliar e monitorar LLMs. Também pode ser usado para técnicas de evaluation. Ele utiliza de técnicas de feedback, com modelos de relevância ou classificadores de sentimento, para usar avaliações com RAG, incluindo a relevância do contexto, relevância da resposta e fundamentação. No TruLens o RAG garante a precisão e a relevância da saída.
Essa ferramenta permite a customização ou pré-definição de ferramentas de feedback via Python, permitindo que as avaliações sejam adaptáveis aos requisitos. Além disso, o TruLens também usa técnicas de embedding models para converter informações pré definidas em vetores numéricos, simplificando encontrar o texto relevante.
2. Desvantagens/LImitações:
Funções de Feedbacks: Seu desempenho depende da função das funções de feedback escolhidas.
3. Vantagens:
Open Source: É uma ferramenta de código aberto, permitindo acesso gratuito e possibilitando a personalização e adaptação conforme as necessidades dos desenvolvedores.
Integração com Diferentes Ferramentas: Facilita a integração com diferentes ferramentas, como langchain e llama index.
Customização com as Funções de Feedback: Permite que os usuários adicionem funções de feedback personalizadas para adaptar o processo de avaliação a requisitos específicos, oferecendo grande flexibilidade.
Guidance AI
1. Definição
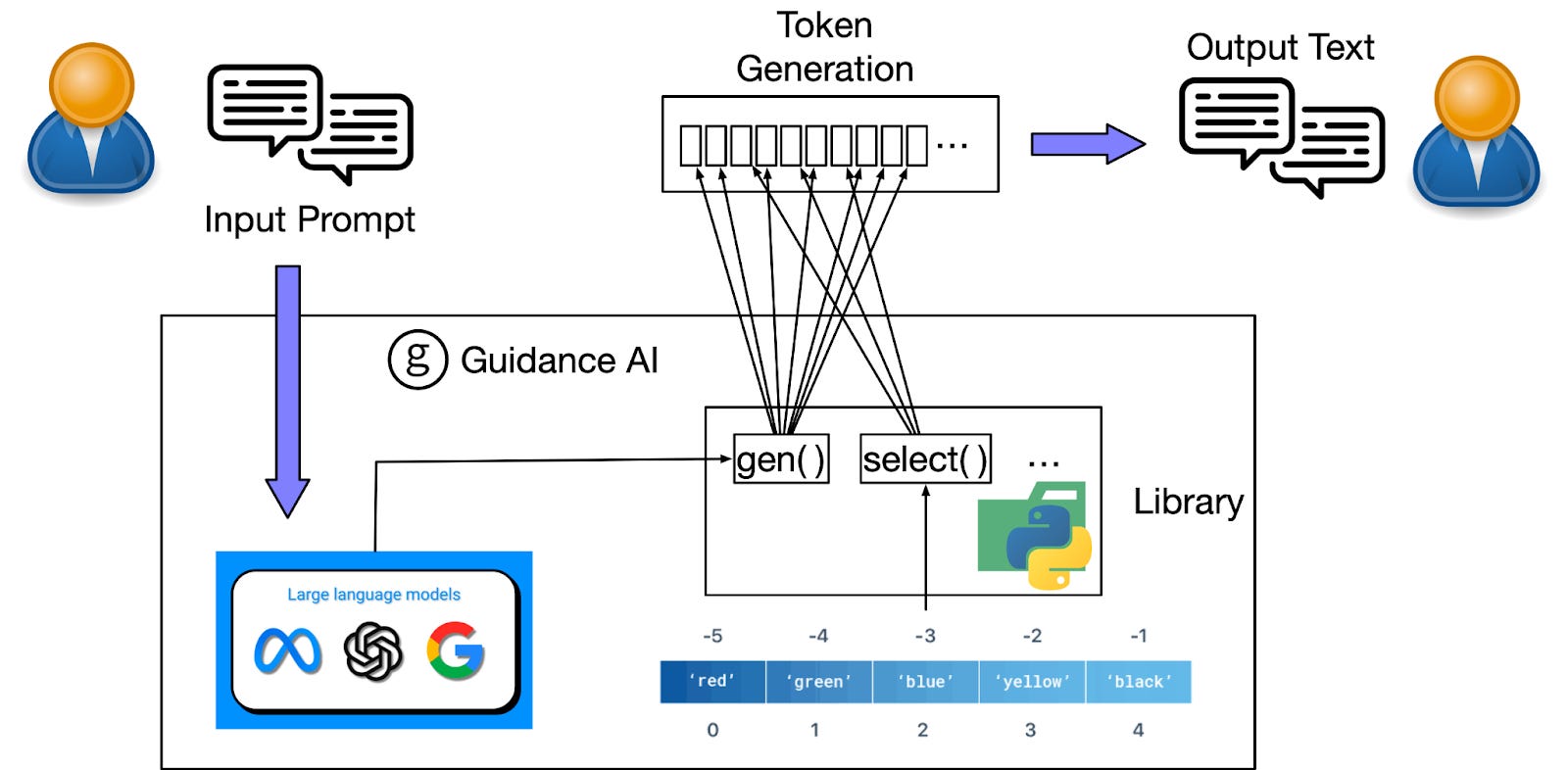
Guidance AI é um paradigma de programação que oferece controle e eficiência superiores em comparação com métodos convencionais de prompting e chaining. Este paradigma permite aos usuários restringir gerações utilizando regex e CFGs, além de integrar controle e geração de texto de maneira contínua. A ferramenta integra geração de texto, prompts e controle lógico em um fluxo contínuo em um ambiente Python, aprimorando a abordagem de processamento de texto em modelos de linguagem de larga escala (LLMs). O Guidance tem uma ordem de execução linear bem definida, correspondente à sequência de tokens processados pelo modelo de linguagem.
2. Limitações e desvantagens:
Flexibilidade: Não possui muita flexibilidade na implementação para adição de outras funções.
Efetividade Limitada: Guardrails baseados em prompts podem não cobrir todos os casos de uso e contextos potenciais, especialmente em aplicações com muita variação ou complexidade. Eles podem falhar em capturar nuances ou excepcionar situações inesperadas.
Dependência do Modelo: Depende da capacidade do modelo de linguagem de interpretar e seguir os prompts corretamente, o que nem sempre é garantido.
3. Vantagens:
Sintaxe Intuitiva: Baseado na linguagem de template Handlebars, o Guidance AI oferece uma sintaxe simples e fácil de usar, facilitando a inserção de variáveis em prompts.
Compatibilidade Ampla: O Guidance AI suporta uma variedade de LLMs e pode integrar-se facilmente com modelos HuggingFace, o que aumenta sua versatilidade e aplicabilidade.
Otimização: Utiliza aceleração para reutilizar caches de chave-valor e reduzir tempos de execução, além de técnicas como token healing para otimizar os limites dos prompts.
LMQL
1. Definição
O LMQL é uma interface de programação avançada voltada para a geração controlada e segura de conteúdo em modelos de linguagem de larga escala (LLMs). Baseando-se no conceito do Guidance AI, o LMQL eleva o paradigma dos "modelos de prompt" para uma nova linguagem de programação.
O LMQL se apresenta como um superconjunto de Python, permitindo a incorporação de restrições precisas diretamente nas consultas. Isso possibilita controlar desde o conteúdo gerado até a conformidade com formatos específicos, garantindo maior precisão e segurança na saída. A implementação utiliza mascaramento logit e suporte personalizado de operadores para aplicar um controle rigoroso sobre os resultados gerados. Isso garante que o conteúdo produzido pelo LLM siga as restrições definidas de maneira eficiente e precisa.
Possui uma sintaxe projetada para ser similar ao SQL e complementada por recursos de script, o LMQL busca simplificar as interações com LLMs. A linguagem é estruturada em torno de declarações de decodificador, como estratégias argmax, beam e sample, proporcionando uma variedade de métodos para processar a saída do modelo.
2. Limitações/Desvantagens
Efetividade Limitada: Assim como o Guidance AI, por ser baseado em prompts, pode falhar em capturar nuances ou excepcionar situações inesperadas.
Dependência do Modelo: Depende da capacidade do modelo de linguagem de interpretar e seguir os prompts corretamente, o que nem sempre é garantido.
3. Vantagens
Sintaxe Semelhante ao SQL: Por ser parecido com SQL é uma linguagem simples e intuitiva.
Superconjunto Python: Permite a incorporação de lógica de programação dentro das consultas, proporcionando maior flexibilidade e poder expressivo.
Mascaramento Logit e Operadores Personalizados: Oferece um controle ajustado sobre as saídas do modelo, permitindo a aplicação de restrições precisas e específicas. Isso garante maior precisão e segurança no conteúdo gerado.

Referências
Leitura
Understanding Why AI Guardrails Are Necessary: Ensuring Ethical and Responsible AI Use
NVIDIA NeMo Guardrails — NVIDIA NeMo Guardrails latest documentation
Vídeos
A autora deste texto é a Mirela Domiciano, AI Engineer na Tech4Humans.
Arrasou Mirela!!